Recently, I submitted a solution to to the state preparation problem of the Classiq coding competition. The goal was to prepare a lognormal distribution (with \(\mu=0,\sigma=0.1\)) using no more than 10 qubits and within \(0.01\) L2 accuracy. Crucially, the problem allowed to use any discretization when mapping from the wavefunction to the lognormal probability density. I did not have any good idea about how to solve the problem in a scalable way, but was curious how far one can go by a direct optimization of low-depth circuits jointly with the discretization intervals. To my surprise, depth 1 circuits on 10 (and in fact 9) qubits are already sufficient to achieve the target accuracy. I believe this solution would be eligible for a prize, but I submitted it later than other participants.
What follows is the notebook I submitted as a solution. It was intended for referees of the competition, who needed no introduction to the problem. In the end, I do not think this solution is particularly illuminating, so I will not try to turn it into a comprehensible blog post. But I also see no harm publishing it, so here we go.
Readme
Solution
Solution to the problem is the following QASM string and byte-represetation of the np.array containing discretization.
To reproduce this result: ‘run all cells’. The two strings presented above will appear in the very last cell of this notebook. This should take about 10-20 minutes depending on the system, 15 minutes on Colab’s GPU.
Verification
The resulting circuit has single-qubit gates only and is therefore depth 1.
x = np.frombuffer(x_solution_str, dtype=np.float32)print('discretization:', x)qc = QuantumCircuit.from_qasm_str(qasm_solution)print('circuit:')qc.draw(output='mpl')
To verify correctnes I’ve collected several different methods of computing L2 norm here. In the code below I also only use qiskit methods for manipulating quantum ciruicts, so this should be a reliable check.
# This function assumes that all qubits are to be measured for the distribution.def probabilities_from_circuit(qc): state = Statevector.from_instruction(qc) return state.probabilities()def three_l2_errors_from_probabilities(p, x): error_2 = l2.idnm_l2_error(jnp.array(p), jnp.array(x)) error_1 = l2.tnemoz_l2_error(p, x) error_0 = l2.l2_error(p, x)print(f'Error by method 0 (QuantumSage):{error_0}')print(f'Error by method 1 (tnemoz):{error_1}')print(f'Error by method 2 (idnm):{error_2}')def three_l2_errors_from_circuit(qasm_str, x, reverse_bits=True): qc = QuantumCircuit.from_qasm_str(qasm_str)if reverse_bits: qc = qc.reverse_bits()print(f'Circuit depth is {qc.depth()}\n') p = probabilities_from_circuit(qc) three_l2_errors_from_probabilities(p, x)three_l2_errors_from_circuit(qasm_solution, x)
Circuit depth is 1
Error by method 0 (QuantumSage):0.006361703002515892
Error by method 1 (tnemoz):0.005891621296138897
Error by method 2 (idnm):0.005880733951926231
Approach
I used fairly straightforward numerical optimization. I was interested if the target lognormal distribution can be approximated by small-depth circuits optimized directly. In other words, I minimized numerically the L2 error as a function of angles in the circuit and discretization intervals.
To my surprise, 9 and 10 qubits circuits with the smallest depth possible (containing only single-qubit gates) are able to give a good enough approximation below the threshold error. The freedom to adjust discretization seems crucial for low-depth circuits.
I also looked how well can one approximate the target distribution for a given number of qubits, assuming that the probability density can take any shape. This corresponds to the maximally expressive circuit, where all \(2^n\) amplitudes can be controlled precisely. Of course I didn’t optimize circuits of such depth. Rather, I optimized values of discrete functions directly. Interestingly, I found that the best possible approximation is not significanltly better than the approximation one can get with depth 1 circuits and the same number of qubits.
Setup
Lognormal distribution and L2 error
The following cells define the lognormal distribution \(f(x)\) itself as well as antiderivatives \(\int dx f(x)\) and \(\int dx f^2(x)\). Andtiderivatives will be useful for computing the L2 error.
def lognormal(x): s =0.1 mu =0return1/ (jnp.sqrt(2* jnp.pi) * x * s) * jnp.exp(-(jnp.log(x) - mu) **2/2/ s **2)def lognormal_int(x):return erf(5* jnp.sqrt(2) * jnp.log(x)) /2def lognormal_squared_int(x):return erf(10* jnp.log(x) +1/20) /2/ jnp.sqrt(jnp.pi) *5* jnp.power(jnp.e, 1/400)# Uncomment to verify correctness of antiderivatives# x = jnp.linspace(0.01, 2, 100)# print(jnp.allclose(vmap(lognormal)(x), vmap(grad(lognormal_int))(x)))# print(jnp.allclose(vmap(lognormal)(x)**2, vmap(grad(lognormal_squared_int))(x)))
Now we will define a simple class collecting some useful data about piecewise constant functions.
class DiscreteFunction:@staticmethoddef condlist(x, grid):return [(g_left < x) & (x <= g_right) for g_left, g_right inzip(grid, grid[1:])]def__init__(self, grid, values):assertlen(grid) ==len(values) +1, f'Number of grid points {len(grid)} does not match number of values {len(values)}.'self.grid = gridself.values = valuesself.probabilities = values * (grid[1:]-grid[:-1])def f(x):return jnp.piecewise(x, DiscreteFunction.condlist(x, grid), self.values)self.f = fdef plot(self, x=None):if x isNone: x = jnp.linspace(0.5, 1.5, 100) plt.plot(x, [self.f(xi) for xi in x]) # jit or vmap here gives an error for some reason. Without them unnecessarily slow. plt.plot(x, vmap(lognormal)(x))@classmethoddef from_probabilities(cls, grid, probs): values = probs/(grid[1:]-grid[:-1])return cls(grid, values)
Here is the function that computes the L2 error between a given discrete function and the lognormal distribution. I used the equation
\[L2=\int_a^b (v-p(x))^2=D^{-1}p(x)^2\Big|^a_b-2 v D^{-1} p(x)\Big|^a_b+v^2 (b-a)\]
This is an error of approximating function \(p(x)\) by a constant \(v\) on an interval \((a,b)\). That this function is correct is confirmed by comparison with other independent methods which I presented above. This (a bit fancy) form is useful for speed in my numerical optimization.
I use JAX for numerical optimization. It is very flexible and efficient, by lacks some of the high level API present in other libraries. The code below is only to setup numerical minimization with JAX, it has no relation to the problem. It is included here only in order to make the notebook self-contained.
I found it very istructive to see what accuracy can be achieved if one can fully control values of the discrete function. Empirically, the best strtategy seems to
First optimize values of the discrete function with fixed discretization.
Continue by optimizing values and adjusting discretization intervals jointly.
Fitting values only
Here is the function that does the first part of the job.
Here is the best this method can do with 10 qubits starting from random initial values between 0 and 1 (you can change the number of qubits if you wish). The histogram shows density of the grid points. At this point they are distributed uniformly.
Now we introduce the second optimization procedure, which also adjusts discretization intervals.
One technical subtlety here is that the grid points should never go past each other. In order to prevent that I use auxilary variables, which are square roots of the distances between neighboring grid points, grid_roots. Even if some grid_root becomes negative the distance between the grid points grid_root**2 stays positive.
VG = namedtuple('ValuesGrid', ['values', 'grid_roots'])def grid_to_roots(grid): all_points = jnp.concatenate([jnp.array([0]), grid]) # Append '0' to the left. cells = all_points[1:] - all_points[:-1]return jnp.sqrt(cells)def roots_to_grid(roots):""" A bit of complicated syntaxis to restore grid from roots in a jax-compatible way.""" cells = roots **2 masks = jnp.tri(len(roots)) pre_grid = vmap(lambda x: cells * x)(masks)return pre_grid.sum(axis=1)def fit_values_and_grid(discrete_function, opt_options=OptOptions()): initial_grid_roots = grid_to_roots(discrete_function.grid) initial_values = discrete_function.values@jitdef loss(vg): grid = roots_to_grid(vg.grid_roots) df = DiscreteFunction(grid, vg.values)return l2_error(df) initial_params = VG(initial_values, initial_grid_roots) results = mynimize(loss, initial_params, opt_options)return OptResult(results, loss, opt_options)
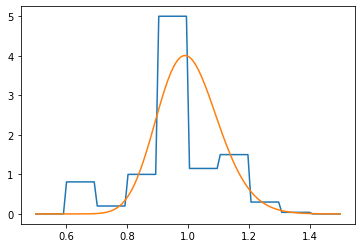
Here is the best fit to the lognormal distribution this procedure is able to find. Note that grid points are no longer distributed uniformly but clamp near the regions with the highest slope, as they should (this is in fact better visible at smaller qubit count). Note that here we initialized the optimization with values found at the previous stage. If we were to initialize them randomly, the result would be much worse. Note also a smaller learning rate at this stage.
First I will define a very simple MyCircuit class that bundles qiskit representation with jax-compatible unitary. For the purposes of this notebook, we only need to place one gate on each qubit.
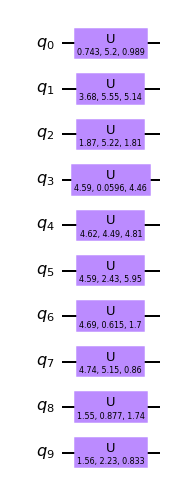
def U_gate(a): theta, phi, lmbda = areturn jnp.array([[jnp.cos(theta/2), -jnp.exp(1j*lmbda)*jnp.sin(theta/2)], [jnp.exp(1j*phi)*jnp.sin(theta/2), jnp.exp(1j*(phi+lmbda))*jnp.cos(theta/2)]])class MyCircuit:def__init__(self, num_qubits):self.num_qubits = num_qubitsdef qiskit_circuit(self, angles):assertlen(angles) ==3*self.num_qubits, f'Number of qubits {self.num_qubits} and angle triples {len(angles)} does not match.' qc = QuantumCircuit(self.num_qubits) angles = np.array(angles) # Qiskit does not accept JAX arrays.for i, (theta, phi, lmbda) inenumerate(angles.reshape(self.num_qubits, 3)): qc.u(theta, phi, lmbda, i)return qcdef unitary(self, angles): gates = vmap(U_gate)(angles.reshape(self.num_qubits, 3))returnreduce(jnp.kron, gates)def _verify(self, angles): u_qs = Operator(self.qiskit_circuit(angles).reverse_bits()).data u_jax =self.unitary(angles)return jnp.allclose(u_qs, u_jax)
Quantum circuit transforms the input state. Amplitudes of the output state encode the values of the discrete function that we use to fit the lognormal distribution. Here we construct a function that takes a quantum circuit and returns the L2 error of the corresponding approximation.
The highly asymmetric shape of the fitting function here is typical and continutes to higher qubits. At the first glance, there seems to be little hope of making the construction work. However, as we see right now, adjusting the discretization ranges cuts the deal.
Fitting angles and grid
Here is the procedure that fits angles and grid together. We bundle it with the previous step into a single simple function fit_circuit that does all the work.
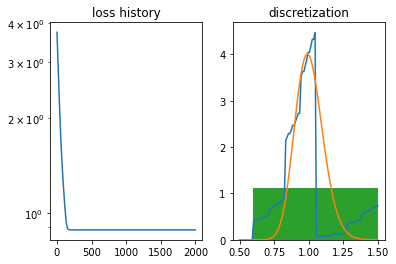
AG = namedtuple('AnglesGrid', ['angles', 'grid_roots'])def fit_angles_and_grid(initial_angles, initial_grid, opt_options=OptOptions()): num_qubits =int(len(initial_angles)/3)assertlen(initial_grid) ==2**num_qubits+1, f'Grid length {len(grid)} does not match number of qubits {num_qubits}.' circuit = MyCircuit(num_qubits)@jitdef loss(ag): u = circuit.unitary(ag.angles) grid = roots_to_grid(ag.grid_roots)return loss_from_unitary(grid, u) initial_grid_roots = grid_to_roots(initial_grid) initial_params = AG(initial_angles, initial_grid_roots) results = mynimize(loss, initial_params, opt_options)return OptResult(results, loss, opt_options)def fit_circuit(num_qubits):print('Initial optimization of angles:') grid = jnp.linspace(0.6, 1.5, 2**num_qubits+1) res = fit_angles(grid, num_qubits)print(res)print('\nOptimization of angles and grid:') circuit = MyCircuit(num_qubits) initial_angles = res.best_params.angles initial_grid = grid opt_options = OptOptions(learning_rate=1e-4, num_iterations=10000) res = fit_angles_and_grid(initial_angles, initial_grid, opt_options)print(res) best_probs = probabilities_from_unitary(circuit.unitary(res.best_params.angles)) best_grid = roots_to_grid(res.best_params.grid_roots) df_fit = DiscreteFunction.from_probabilities(best_grid, best_probs) plt.subplot(1, 2, 1) res.plot_loss_history() plt.title('loss history') plt.subplot(1, 2, 2) df_fit.plot() plt.hist(np.array(df_fit.grid), bins=int(len(df_fit.grid)/5), density=True); plt.title('discretization')return circuit.qiskit_circuit(res.best_params.angles).qasm(), best_grid
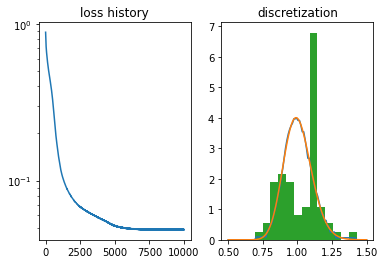
Here is what happens for 6 qubits when we follow up initial angle optimization with the grid optimization.
qasm, grid = fit_circuit(6)
Initial optimization of angles:
OptResult: best_loss 0.884075403213501.
Optimization of angles and grid:
OptResult: best_loss 0.04849757254123688.
The optimization results improved dramatically. We are able to achive \(5\times 10^{-2}\) error already on six qubits. As we can anticipate, using all 10 qubits helps a lot.
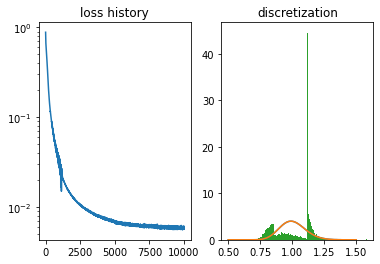
Final solution
Here is the final solution. The qasm file and grid specified at the beginning of this notebook were produced here. On Colab’s GPU this takes about 10 minutes to run.
qasm, grid = fit_circuit(10)
Initial optimization of angles:
OptResult: best_loss 0.8839455246925354.
Optimization of angles and grid:
OptResult: best_loss 0.005602838937193155.